Recherche
A la pêche à la LI(g)NE … avec le nouvel outil bio-informatique CLIFinder
Publié le 26 octobre 2018 – Mis à jour le 26 octobre 2018
Un texte de la Minute Recherche par Catherine Barrière (GReD, unité mixte de recherche Inserm, CNRS, Université Clermont Auvergne). La molécule d’ADN est le support de l’information génétique contenu dans toutes les cellules de notre organisme.
La molécule d’ADN est le support de l’information génétique contenu dans toutes les cellules de notre organisme. Dans le cadre du fonctionnement cellulaire, la lecture de parties de l’ADN (gènes) produit des molécules nommées transcrits qui jouent un rôle dans la cellule soit directement, soit après traduction en protéines. Les niveaux d’expression des transcrits sont généralement finement régulés au cours de la vie d’une cellule. Leur dérégulation peut avoir des conséquences néfastes pour la cellule et notamment conduire au développement de pathologies dont le cancer.
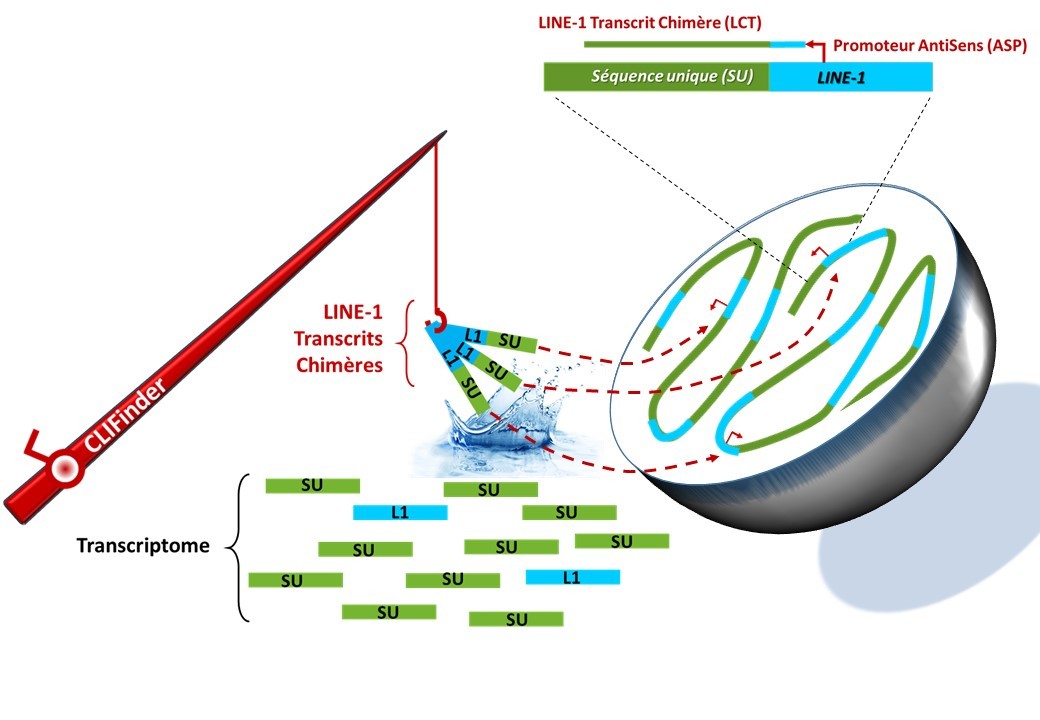
Chez l’homme, la molécule d’ADN est constituée pour moitié d’éléments de courte taille dits «répétés» car présents en des centaines de milliers d’exemplaires. Compte tenu de leur grand nombre et de leur similitude de séquences, l’implication de ces éléments répétés en biologie humaine est difficile à étudier. Pour autant, quelques exemples dans la littérature indiquent que des éléments répétés appelés LINE-1 (ou L1) pourraient être responsables de la dérégulation de l’expression d’acteurs majeurs connus pour être impliqués dans les processus de tumorigenèse. En effet, certains L1 ont la capacité de produire des lectures particulières, débutant dans le L1 et se poursuivant dans la séquence d’ADN voisine, formant des transcrits dits « chimères » (ou LCT). Ces LCT peuvent alors être responsables de la dérégulation de l’expression de gènes contenus dans les séquences d’ADN voisines des L1, notamment acteurs de la tumorigenèse. Toutefois, l’étendue de la production de LCT à l’échelle de l’ensemble du génome humain en contexte normal et tumoral reste inconnue.
CLIFinder (Chimeric Line Finder) est un nouveau logiciel bio-informatique dédié à l’identification pangénomique de LCT à partir de données de séquençage haut-débit. Celui-ci permet d’identifier l’intégralité de séquences transcrites dans un tissu (ou transcriptome). Ainsi, CLIFinder est capable de «pêcher», parmi toutes les séquences d’un transcriptome, de nombreux LCT composés d’une séquence de L1 et d’une séquence unique du génome. L’outil CLIFinder est aujourd’hui à la disposition de la communauté scientifique pour réaliser des analyses extensives dans différents tissus normaux mais aussi pathologiques. Notamment, de nombreux LCT ont été mis en évidence spécifiquement dans des tissus tumoraux, et seraient susceptibles de déréguler des acteurs importants de la tumorigenèse tels que des oncogènes ou des gènes suppresseurs de tumeur.
Chez l’homme, la molécule d’ADN est constituée pour moitié d’éléments de courte taille dits «répétés» car présents en des centaines de milliers d’exemplaires. Compte tenu de leur grand nombre et de leur similitude de séquences, l’implication de ces éléments répétés en biologie humaine est difficile à étudier. Pour autant, quelques exemples dans la littérature indiquent que des éléments répétés appelés LINE-1 (ou L1) pourraient être responsables de la dérégulation de l’expression d’acteurs majeurs connus pour être impliqués dans les processus de tumorigenèse. En effet, certains L1 ont la capacité de produire des lectures particulières, débutant dans le L1 et se poursuivant dans la séquence d’ADN voisine, formant des transcrits dits « chimères » (ou LCT). Ces LCT peuvent alors être responsables de la dérégulation de l’expression de gènes contenus dans les séquences d’ADN voisines des L1, notamment acteurs de la tumorigenèse. Toutefois, l’étendue de la production de LCT à l’échelle de l’ensemble du génome humain en contexte normal et tumoral reste inconnue.
CLIFinder (Chimeric Line Finder) est un nouveau logiciel bio-informatique dédié à l’identification pangénomique de LCT à partir de données de séquençage haut-débit. Celui-ci permet d’identifier l’intégralité de séquences transcrites dans un tissu (ou transcriptome). Ainsi, CLIFinder est capable de «pêcher», parmi toutes les séquences d’un transcriptome, de nombreux LCT composés d’une séquence de L1 et d’une séquence unique du génome. L’outil CLIFinder est aujourd’hui à la disposition de la communauté scientifique pour réaliser des analyses extensives dans différents tissus normaux mais aussi pathologiques. Notamment, de nombreux LCT ont été mis en évidence spécifiquement dans des tissus tumoraux, et seraient susceptibles de déréguler des acteurs importants de la tumorigenèse tels que des oncogènes ou des gènes suppresseurs de tumeur.
Références
Pinson ME, Pogorelcnik R, Court F, Arnaud P, Vaurs-Barriere C.CLIFinder: Identification of LINE-1 Chimeric Transcripts in RNA-seq data.
Bioinformatics. 2017 Oct 23. doi: 10.1093/bioinformatics/btx671.